Figure 1: Overview of SQL joins by C.L. Moffatt from codeproject.com , which includes excellent explanations for each diagram as well (format howto)
~22m skim, 4,600 words, updated Jan 24, 2025
For table querying and manipulation.
Programming is tough. Especially at first.
Whatever you are learning or writing, keep in mind that every language was created with a set of principles and use cases in mind - some more than others.
Learn to reject your ego. Learn to love burning code.
Name things what they are. Begin with your program’s final state in mind!
Structured Query Language (SQL) is used to retrieve and modify information in a relational database management system like MySQL, PostgreSQL, SQLite , Microsoft SQL, Oracle, and others. Relational databases store data in large relational tables, where each row must conform to the types specified in the table columns, where cell contents must be either data, nothing, or a reference to a row in another table.
Typically SQL is pronounced “SEQUEL” as this was its original name when invented by Donald Chamberlin and Raymond Boyce at IBM in the 70s.
Use the W3Schools Try-It Editor to tinker with SQL now.
Object Relational Mappers (ORMs) are abstractions used by web developers to interact with relational databases.
Modern developers could live out a career without ever touching SQL due to the variety of well built ORMs that exist to translate objects built in an object-oriented language to SQL queries for insertion, retrieval, and manipulation. This is unfortunate in the same way a lack of knowledge about a CPU, machine code, assembly languages, or C is unfortunate: It means the programmer in question is operating on blind abstraction. This is obviously useful right up to the moment when performance tuning, a bug, or some other issue necessitating critical introspection of a codebase appears.
All of the aforementioned DBMS (Database Management System) flavors like MySQL and PostgreSQL use similar dialects of a common SQL standard. Statements are often similar or identical, but each flavor has slight differences in syntax.
Flavors differentiate themselves with the features they offer the business and developer, including:
It’s easy to install PostgreSQL on alpine linux with this set of commands. This will install the database system, add it as a default program to run, and open the firewall to allow external access to the database.
sudo su
apk update
apk add postgresql
service start postgresql
rc-update add postgresql default
ufw allow postgresql/tcpYou can then find the configuration files by writing:
psql -U postgres -c 'SHOW config_file'
# /etc/postgresql/postgresql.conf
psql -U postgres -c 'SHOW data_directory'
# /var/lib/postgresql/13/dataEnable remote connections with these actions:
echo "host all all 0.0.0.0/0 md5" >> /var/lib/postgresql/13/data/pg_hba.conf
echo "listen_addresses='*'" >> /var/lib/postgresql/13/data/postgresql.confLocking this down once you find you can connect is a good idea.
Check this and that for further setup guidance.
For running commands use DbGate
In the psql shell you can create, list, and drop whole databases. Use
caution with these commands.
postgres=# CREATE DATABASE chicken_coop;
CREATE DATABASE
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
--------------+----------+----------+---------+---------+-----------------------
chicken_coop | postgres | UTF8 | C | C.UTF-8 |
dog_app | ryan | UTF8 | C | C.UTF-8 |
pet_shop | ryan | UTF8 | C | C.UTF-8 |
postgres | postgres | UTF8 | C | C.UTF-8 |
postgres=# DROP DATABASE chicken_coop;
DROP DATABASETo change the database you are in use \c.
postgres=# \c dog_app
You are now connected to database "dog_app" as user "postgres".From here you can use your usual SQL commands. Show tables with \dt.
This section contains a short usage guide for each of the common SQL commands, with one or two composition examples.
CREATE TABLE <name> (
column_name type,
column_name type
-- ...etc.
);
CREATE TABLE tweets (
username VARCHAR(100),
tweet_content VARCHAR(140),
favourites INT
);ALTER TABLE <table> ADD <column name> <type>;
ALTER TABLE <table> RENAME TO <new_table_name>;If a table is no longer required, it can be dropped from the database.
Creating an index is, in essence, an instruction to the database to hold additional data about a column to speed up queries.
A simple single-column index to speed up queries:
CREATE INDEX idx_media_item_created ON media.items (created);A composite index enables faster querying when multiple columns are frequently accessed at the same time in a single query.
CREATE INDEX idx_systemx_digitaltwin_person ON digitaltwin.person (country, firstname);Generally, PostgreSQL would encourage you to drop and recreate an index. You could always reindex to bump performance.
-- Reindex to see if this helps
REINDEX INDEX media.idx_institution_urlkey;
-- You can always nuke it
DROP INDEX IF EXISTS idx_media_item_created;DROP INDEX idx_media_item_created;Given a table, provide the columns and data you’d like to insert.
INSERT INTO some_table(col1, col2) VALUES ('data1', 111);
CREATE TABLE people (
first_name VARCHAR(100),
last_name VARCHAR(100),
age int
);
INSERT INTO people(first_name, last_name, age) VALUES
('Michael', 'Sweeny', 23),
('Phillip', 'Frond', 38),
('Calvin', 'Kleinfelter', 65);Here’s a sample table:
CREATE TABLE employees (
id BIGSERIAL PRIMARY KEY,
last_name VARCHAR(100) NOT NULL,
first_name VARCHAR(100) NOT NULL,
middle_name VARCHAR(100),
age INT NOT NULL,
current_status VARCHAR(100) NOT NULL DEFAULT 'employed'
);Providing the requred values and allowing the defaults to autopopulate:
# insert into employees(first_name, last_name, age) values ('greg', 'torbo', 21);
INSERT 0 1
# select * from employees;
id | last_name | first_name | middle_name | age | current_status
----+-----------+------------+-------------+-----+----------------
1 | torbo | greg | | 21 | employedRetrieves data from a table.
SELECT <columns or * for all> FROM <table>;SELECT id, name, description FROM products;See the section on querying for more information.
Given values and a condition, update rows in a table.
UPDATE <table> SET <column>=<value>, <column2>=<value> WHERE <condition>;
UPDATE people SET max_hot_wings=20 WHERE id=8;The DELETE FROM clause enables the conditional removal of rows.
DELETE FROM <table> WHERE <condition>;
DELETE FROM people WHERE max_hot_wings < 50;Can be provided in either of these formats:
CREATE TABLE board_members (
member_id int PRIMARY KEY, -- option one
name VARCHAR(100),
age INT,
PRIMARY KEY(member_id) -- option two
);This is also a good place to use AUTO_INCREMENT in other databases,
which provides a default of the next integer. Postgres provides the
SERIAL type which has the same function.
When designing tables, many different constraints can be provided.
When creating a table, you may specify restrictions for data entering
your tables. For instance, NOT NULL or UNIQUE.
PRIMARY KEY is meant to be used to uniquely identify rows in
lookups, though can only be used once.UNIQUE can be used many times and prevents duplicate inserts.NOT NULL ensures data is given for the column.DEFAULT allows you to provide a value if none is passed.For instance:
CREATE TABLE media.items (
id BIGSERIAL PRIMARY KEY,
uuid UUID NOT NULL DEFAULT gen_random_uuid (),
created TIMESTAMP NOT NULL DEFAULT NOW(),
title TEXT,
posted TIMESTAMP,
-- foreign keys
id_source BIGINT REFERENCES media.sources (id)
);The real power of SQL is the composition and filtering of data in various tables to produce business-driving insights.
The lexical order that queries must be written in is as follows:
| Clause | Function |
|---|---|
SELECT | Provide target columns |
FROM | Provide target table |
JOIN | Combine tables with columns in common |
WHERE | Filter the results |
GROUP BY | Summarize similar columns |
HAVING | When group by is used, filter the columns |
ORDER BY | Sort the results |
LIMIT | Limit the number of rows returned |
SFJWGHOL!? San Francisco Jehovah’s Witnesses Get High on Life? Ha.
I asked ChatGPT and it gave me a few more good ones:
-- sfjwghol select from join where groupby having orderby limitExecution order is a different and technical matter.
-- Everything from the table
SELECT * FROM users;
-- Just a few columns
SELECT id, name FROM users;
-- Aliased Columns
SELECT id, hot_wing_max as 'Maximum Hot Wings' FROM users;The distinct keyword enables the filtering of output to unique values.
SELECT DISTINCT province FROM address_book;The where keyword is a functional filter operation. You can use all of
the typical comparison operators here: =, !=, >, <, >=, and
<=. A single = sign is used for equality - this ain’t JavaScript!
SELECT * FROM users WHERE hot_sauce_max_temp >= 8;You may pattern-match to filter and find rows in your database. An
underscore (_) will match any character and percent (%) will match
zero or more missing characters.
-- Match for 'Eric', 'Erik', etc.
SELECT * FROM users WHERE name LIKE 'eri_';
-- Match for 'Alice', 'Aaron', etc
SELECT * FROM users WHERE name LIKE 'a%';Note: LIKE is NOT case sensitive.
For finding data with null column values.
-- Find users with a favourite hot sauce
SELECT * FROM users WHERE favourite_hot_sauce IS NOT NULL;
-- Find users without a favourite hot sauce
SELECT * FROM users WHERE favourite_hot_sauce IS NULL;This clause selects values between the two terms inclusively. To get numbers from 0 to 10, you would query:
SELECT * FROM numbers WHERE value BETWEEN 0 AND 10;This has some interesting behavior with strings - as ‘Branch’ would be past ‘B’ the next letter must be used to limit a query.
AND ensures both conditions are met.
-- Select people who can eat a lot of very hot wings
SELECT * FROM users WHERE
hot_sauce_max_temp > 9
AND hot_wing_max > 10;OR ensures either condition is met.
-- Select people who like specific sauces
SELECT * FROM users WHERE
favourite_hot_sauce = 'Marys'
or favourite_hot_sauce = 'Rogers Black Reaper Cherry';Queries that require sorted results can be organized with the ORDER BY
clause.
ORDER BY <column> ASC; -- Ascending (A->Z)
ORDER BY <column> DESC; -- Descending (Z->A)
-- Rank hot sauce enjoyers by max temperature
SELECT * FROM users WHERE
favourite_hot_sauce IS NOT NULL
ORDER BY hot_sauce_max_temp DESC;Restrict the number of rows returned.
SELECT * FROM users WHERE
favourite_hot_sauce IS NOT NULL
ORDER BY hot_sauce_max_temp DESC
LIMIT 3; -- Return only the top 3 spiciest hot sauce enjoyersCASE enables control flow in SQL.
SELECT <col>,
CASE
WHEN <col_b> = <something> THEN '<result>'
WHEN <col_b> = <something_else> THEN '<result>'
ELSE '<result>'
END AS <new_col_name>
FROM <table>;Most SQL engines provide at least COUNT, SUM, MAX, MIN, AVG, and ROUND
as aggregate functions to reduce query results.
-- Count
SELECT COUNT(*) AS user_count FROM users;
-- Sum
SELECT SUM(oz_gold) FROM users;
-- Max/Min/Average
SELECT MAX(hot_sauce_max_temp) FROM users;
SELECT MIN(hot_sauce_max_temp) FROM users;
SELECT AVG(hot_sauce_max_temp) FROM users;
-- Round
-- Here we round to 2 decimal places
SELECT name, ROUND(oz_gold, 2) FROM users;
-- Round & Average together
SELECT ROUND(AVG(oz_gold), 2) FROM users;Rather than getting aggregates for the entire table, we can group the rows in order to take statistics and averages for rows with common properties.
SELECT favourite_hot_sauce, SUM(tacos_eaten) from cantina_users
-- WHERE spice_tolerance_rating > 5 -- only count tacos from spice tolerant users
GROUP BY favourite_hot_sauce;
-- favourite_hot_sauce tacos_eaten
-------------------------------------
-- Marcella House Sauce 10,0281
-- Frank's RedHot 92In the GROUP and ORDER BY clauses you may use column references to
simplify your query.
select category, price, AVG(downloads) as average_downloads FROM fake_apps
where category = 'Travel'
group by 1, 2 order by 3 desc;What if the post-grouping results must be filtered?
SELECT favourite_hot_sauce, SUM(tacos_eaten) as tacos from cantina_users
GROUP BY favourite_hot_sauce
-- Only count hot sauces that have been used on over 1000 tacos:
HAVING tacos > 1000;
-- In a query, having is | here |
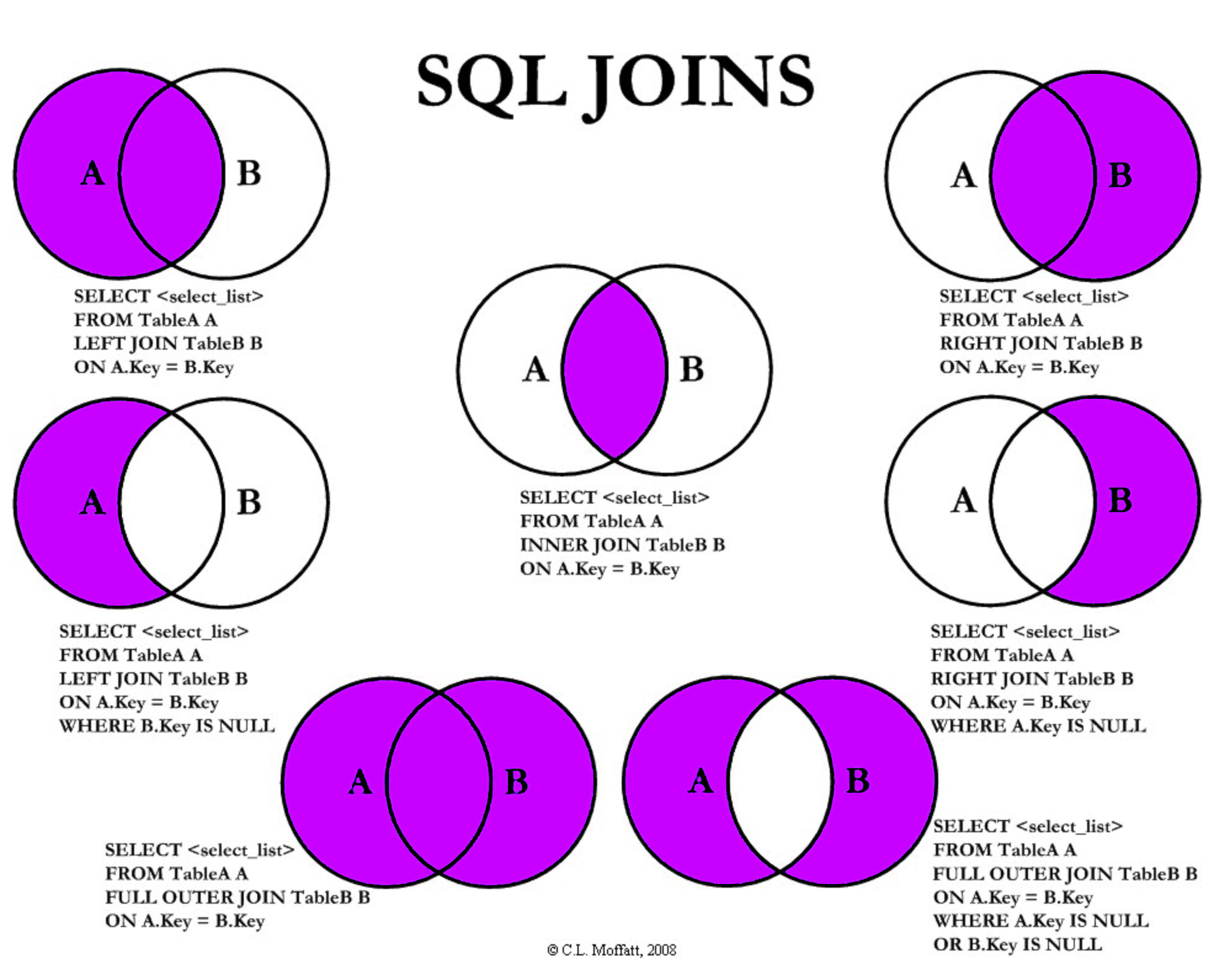
-- select from join where groupby **having** orderby limitFigure 1: Overview of SQL joins by C.L. Moffatt from codeproject.com , which includes excellent explanations for each diagram as well (format howto)
SELECT * FROM TableA A
INNER JOIN TableB B
ON A.Key=B.Key;Given two tables, ensures that rows are returned which have a matching element in both the first and second table. Rows from the first or second table with no match will not be included in the result.
SELECT * FROM TableA A
LEFT JOIN TableB B --> Left
ON A.Key=B.Key;
SELECT * FROM TableA A
RIGHT JOIN TableB B --> Right
ON A.Key=B.Key;Much like an inner join, but will include the entirety of the first
(left) or second (right) table during the join, returning some values
from the other table as NULL.
SELECT * FROM TableA A
LEFT JOIN TableB B --> Left
ON A.Key=B.Key
WHERE B.Key IS NULL;
SELECT * FROM TableA A
RIGHT JOIN TableB B --> Right
ON A.Key=B.Key
WHERE A.Key IS NULL;;These are useful for finding all the records that don’t have a corresponding entry in the second (right) table (in the case of a right excluding join).
SELECT * FROM TableA A
FULL OUTER JOIN TableB B
ON A.Key=B.Key;This returns everything from both tables - including rows where there is no match in either table.
SELECT * FROM TableA A
FULL OUTER JOIN TableB B
ON A.Key=B.Key
WHERE A.Key IS NULL OR B.Key IS NULL;This will return all the rows from both tables with no match.
Joining without any condition combines each row in table A with every row in table B. This is known as a Cartesian product - it returns every possible combination of rows. Cross joins are useful for reducing a table to come to conclusions.
We could use this to see how many members the taco club had per year
SELECT year, COUNT(*) as clubs from taco_club CROSS JOIN club_years_active
WHERE join_year <= year AND leave_year >= year
GROUP BY year;This could yield a result like so:
| year | clubs |
|---|---|
| 1997 | 3 |
| 1998 | 23 |
| 1999 | 382 |
| 2000 | 902 |
Union enables the joining of tables with the same number of columns and
data types. Particular columns in two unequal tables can be used to form
a single table with a UNION.
-- It was the best of burritos, it was the worst of burritos
SELECT * FROM best_burritos UNION SELECT * FROM worst_burritos;For instance - count the tacos eaten by all members of each taco club, and order with the club that has eaten the most tacos first.
WITH club_tacos_eaten AS (
SELECT taco_club_fk, SUM(tacos_eaten) as club_tacos_eaten from cantina_users
GROUP BY taco_club_fk
) SELECT * FROM club_tacos_eaten
LEFT JOIN taco_clubs ON taco_clubs.id=club_tacos_eaten.taco_club_fk
ORDER BY club_tacos_eaten DESC;This enables complex, multi-stage queries on data.
An open-source community-driven version of Oracle DBMS.
A ‘+’ can be added to most of these commands to display extra
information.
| Command | Description |
|---|---|
\c <db> | Connect to a different database |
\du | Show users |
\l | Show databases |
\dt | Show tables |
\dt *.* | Show all tables in all schemas |
show search_path; | Shows psql search path (list of schema names) |
\d <table name> | Describe a table |
\dn | List schemas |
\df | List functions |
\dv | List views |
\g | Run previous command |
\s | Show command history |
Example usage:
--> Select all the schemas within the current database
observer_dev=> \dn+
List of schemas
Name | Owner | Access privileges | Description
--------+---------------+----------------------+------------------------
media | observeradmin | |
...etc (2 rows)
--> Select all the tables within the 'media' schema
observer_prod=> \dt+ media.*
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------------------+-------+---------------+-------------+---------------+------------+-------------
media | items | table | observeradmin | permanent | heap | 1328 MB |
media | keywords | table | observeradmin | permanent | heap | 8192 bytes |
media | sources | table | observeradmin | permanent | heap | 216 kB |
media | text_analysis_v1 | table | observeradmin | permanent | heap | 8192 bytes |
...etc (6 rows)
--> Select all the indexes for tables in the 'media' schema
observer_prod=> \di+ media.*
List of relations
Schema | Name | Type | Owner | Table | Persistence | Access method | Size | Description
--------+------------------------------------------+-------+---------------+------------------------------+-------------+---------------+------------+-------------
media | idx_institution_urlkey | index | observeradmin | institutions | permanent | btree | 32 kB |
media | idx_media_item_source | index | observeradmin | items | permanent | btree | 20 MB |
media | idx_media_item_uri | index | observeradmin | items | permanent | btree | 127 MB |
media | idx_media_item_uri_institution_unique | index | observeradmin | items | permanent | btree | 129 MB |
media | idx_media_item_uri_source_unique | index | observeradmin | items | permanent | btree | 150 MB |
... etc (13 rows)GENERATE_SERIES can be used as a basis for other queries by providing a simple time-series starting point to accumulate counts or other metrics.
SELECT GENERATE_SERIES(
-- Start time
(DATE_TRUNC('hour', NOW()) - interval '72 hours'),
-- End time
(DATE_TRUNC('hour', NOW())),
-- Interval window
'1 hour') AS hour;This results in a list of timestamps as a basis for further queries.
hour
------------------------
2025-01-07 12:00:00-07
2025-01-07 13:00:00-07
2025-01-07 14:00:00-07
2025-01-07 15:00:00-07
2025-01-07 16:00:00-07
2025-01-07 17:00:00-07
2025-01-07 18:00:00-07
2025-01-07 19:00:00-07
2025-01-07 20:00:00-07
2025-01-07 21:00:00-07
2025-01-07 22:00:00-07This interval can be switched to minutes if more detail is desired.
For instance, this could be used
WITH time_series AS (
SELECT GENERATE_SERIES((DATE_TRUNC('hour', NOW()) - interval '72 hours'),
(DATE_TRUNC('hour', NOW())), '1 hour') AS hour), languages AS (
SELECT DISTINCT
LANGUAGE
FROM media.items), cross_data AS (
SELECT ts.hour, l.language
FROM time_series ts
CROSS JOIN languages l
)
SELECT *
FROM cross_data;To produce data like this
hour | language
------------------------+----------
2025-01-07 12:00:00-07 | mk
2025-01-07 12:00:00-07 | fr
2025-01-07 12:00:00-07 | sk
2025-01-07 12:00:00-07 | tr
2025-01-07 12:00:00-07 | en
2025-01-07 13:00:00-07 | mk
2025-01-07 13:00:00-07 | fr
2025-01-07 13:00:00-07 | sk
2025-01-07 13:00:00-07 | tr
2025-01-07 13:00:00-07 | en
... etcPostGIS extends the capabilities of the PostgreSQL relational database by adding support for storing, indexing, and querying geospatial data.
SELECT * FROM pg_available_extensions WHERE name = 'postgis';If this shows a version installed, enable with:
CREATE EXTENSION postgis;Apart from PostgreSQL, there are plenty of other good SQL engines with different strengths and use cases.
An ultralight on-disk SQL implementation. Codecademy’s learn sql course is taught with this program, and it is extremely easy to run on a student machine. Commonly SQLite is used for single-user databases - whether that is an automatic weapon on the deck of a ship, an app on a cell phone, or a small web application.
Read this amazing article on the origins of SQLite. Here’s an excerpt:
The story begins in a shipyard in Bath, Maine (population: 8,329). Back in the year 2000, Hipp was working for Bath Iron Works, a shipbuilding subsidiary of defense contractor General Dynamics, and was building software for a Navy destroyer (the USS Oscar Austin). The software would operate on crucial data about the ship’s valves (for routing around pipe ruptures), and their stack had included Informix, which unfortunately stopped working whenever the server went down.
“That was embarrassing,” Hipp recalled to Bell. “A dialog box would pop up, they’d double click on the thing, and a dialog box would pop up that says, ‘Can’t connect to database server.’ It wasn’t our fault — we didn’t have any control over the database server. But what do you do if you can’t connect to the server? So we got the blame all the same, because we were painting the dialog box.”
And, as Hipp noted, “it’s a warship.” So besides the ship being continually in use, “the idea is it’s supposed to be able to work if you take battle damage! So it’s more than one pipe breaking. There’s going to be a lot of stuff broken, and people are going to be crazy, and there’s going to be smoke and blood and chaos — and in a situation like that they don’t want a dialog box that says, ‘Cannot connect to database server.’”
Hugo can support the rendering of SQLite code blocks with the custom markup:
--> /themes/yourtheme/layouts/_default/_markup/render-codeblock-sqlite.html
{{- transform.Highlight .Inner "sql" -}}This way, you can execute ‘sqlite’ code-blocks inline in org-mode, given you provide the location of the database at the top of the file.
#+PROPERTY: header-args:sqlite :dir ~/Documents/ :db tmp.db :results outputSELECT * FROM test LIMIT 1;result ;; => 1,2
Also known as T-SQL or Transact-SQL. Beware - lots of weird bits here due to the system’s extremely long history. SQL Server was forked from Sybase SQL Server1 which evolved from Ingres2. PostgreSQL also evolved from Ingres (Post-Ingres-SQL.)
[ ] Hard braces are used around many objects and names to support
legacy systems with unsupported characters in table names.Rather than limit, TOP N can be used:
SELECT TOP 10
*,
LEN(your_string_column) AS string_length
FROM
[schema1].[table1]
ORDER BY
[string_length] DESC;The syntax for searching is also different, especially to search for
hard brackets ([).
SELECT *
FROM [schema1].[table1]
-- Any group of '['
WHERE [filename] LIKE '%[[]%' ESCAPE '\';
-- ESCAPE '\' instructs T-SQL to change its escape character.Enterprise, expensive. PostgreSQL is a suitable migration target for Oracle databases.
This is just awesome. Included because people should think ethically about the things they create, especially fintech software.
“I could have edited the list down to just those aspects that seem relevant to coding, but that would put me in the position of editing and redacting Benedict of Nursia, as if I were wiser than he. And I considered that. But in the end, I thought it better to include the whole thing without change (other than translation into English). In the preface, I tried to make clear that the introspective aspects could be safely glossed over.” - Richard Hipp
This document was originally called a “Code of Conduct” and was created for the purpose of filling in a box on “supplier registration” forms submitted to the SQLite developers by some clients. However, we subsequently learned that “Code of Conduct” has a very specific and almost sacred meaning to some readers, a meaning to which this document does not conform [ 1 ][ 2 ][ 3 ]. Therefore this document was renamed to “Code of Ethics”, as we are encouraged to do by rule 71 in particular and also rules 2, 8, 9, 18, 19, 30, 66, and in the spirit of all the rest.
This document continues to be used for its original purpose - providing a reference to fill in the “code of conduct” box on supplier registration forms.
The founder of SQLite, and all of the current developers at the time when this document was composed, have pledged to govern their interactions with each other, with their clients, and with the larger SQLite user community in accordance with the “instruments of good works” from chapter 4 of The Rule of St. Benedict (hereafter: “The Rule”). This code of ethics has proven its mettle in thousands of diverse communities for over 1,500 years, and has served as a baseline for many civil law codes since the time of Charlemagne.
No one is required to follow The Rule, to know The Rule, or even to think that The Rule is a good idea. The Founder of SQLite believes that anyone who follows The Rule will live a happier and more productive life, but individuals are free to dispute or ignore that advice if they wish.
The founder of SQLite and all current developers have pledged to follow the spirit of The Rule to the best of their ability. They view The Rule as their promise to all SQLite users of how the developers are expected to behave. This is a one-way promise, or covenant. In other words, the developers are saying: “We will treat you this way regardless of how you treat us.”
Sybase SQL Server: https://news.ycombinator.com/item?id=11241594 ↩︎
Pages are organized by last modified.
Title: SQL
Word Count: 4600 words
Reading Time: 22 minutes
Permalink:
→
https://manuals.ryanfleck.ca/sql/